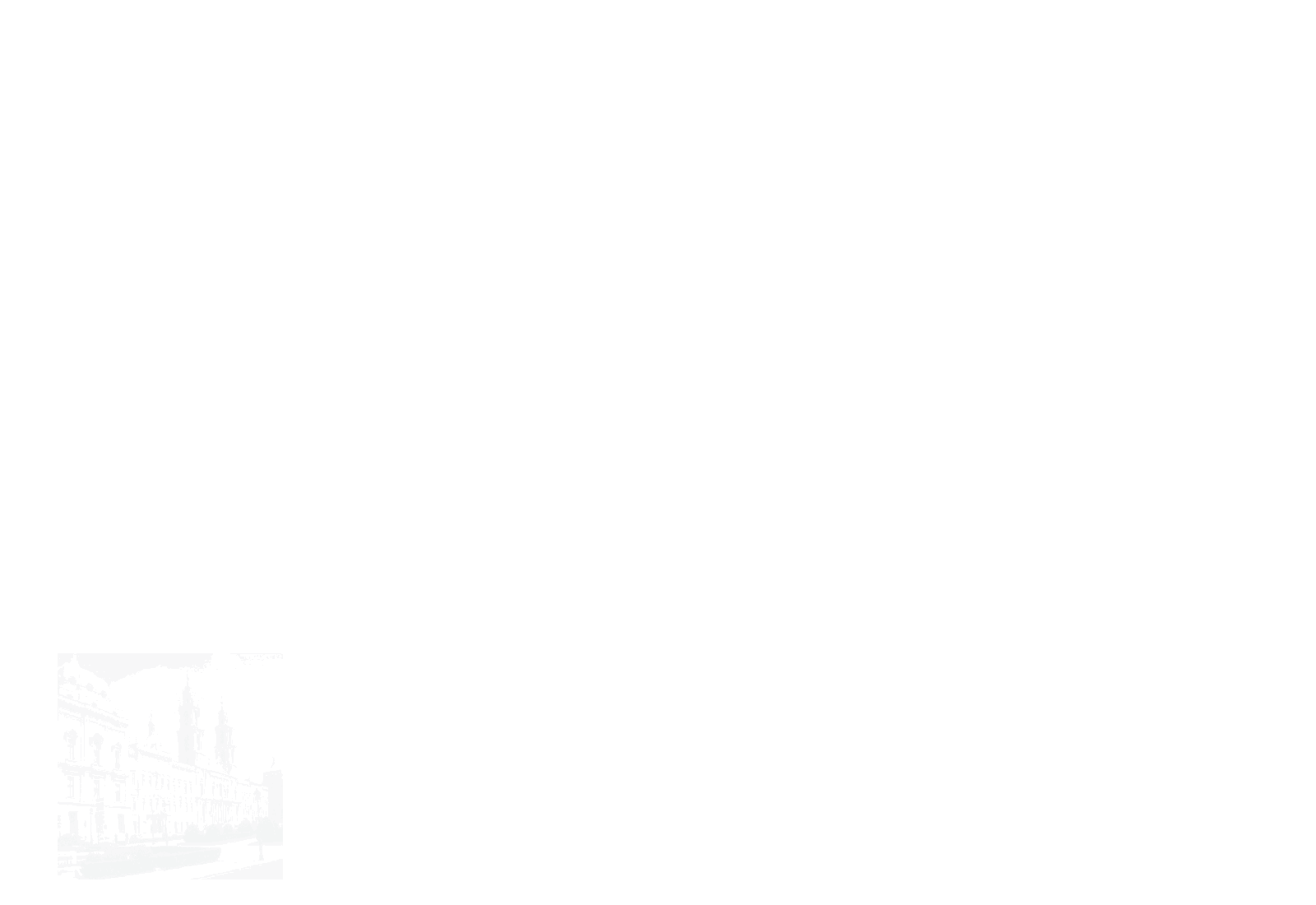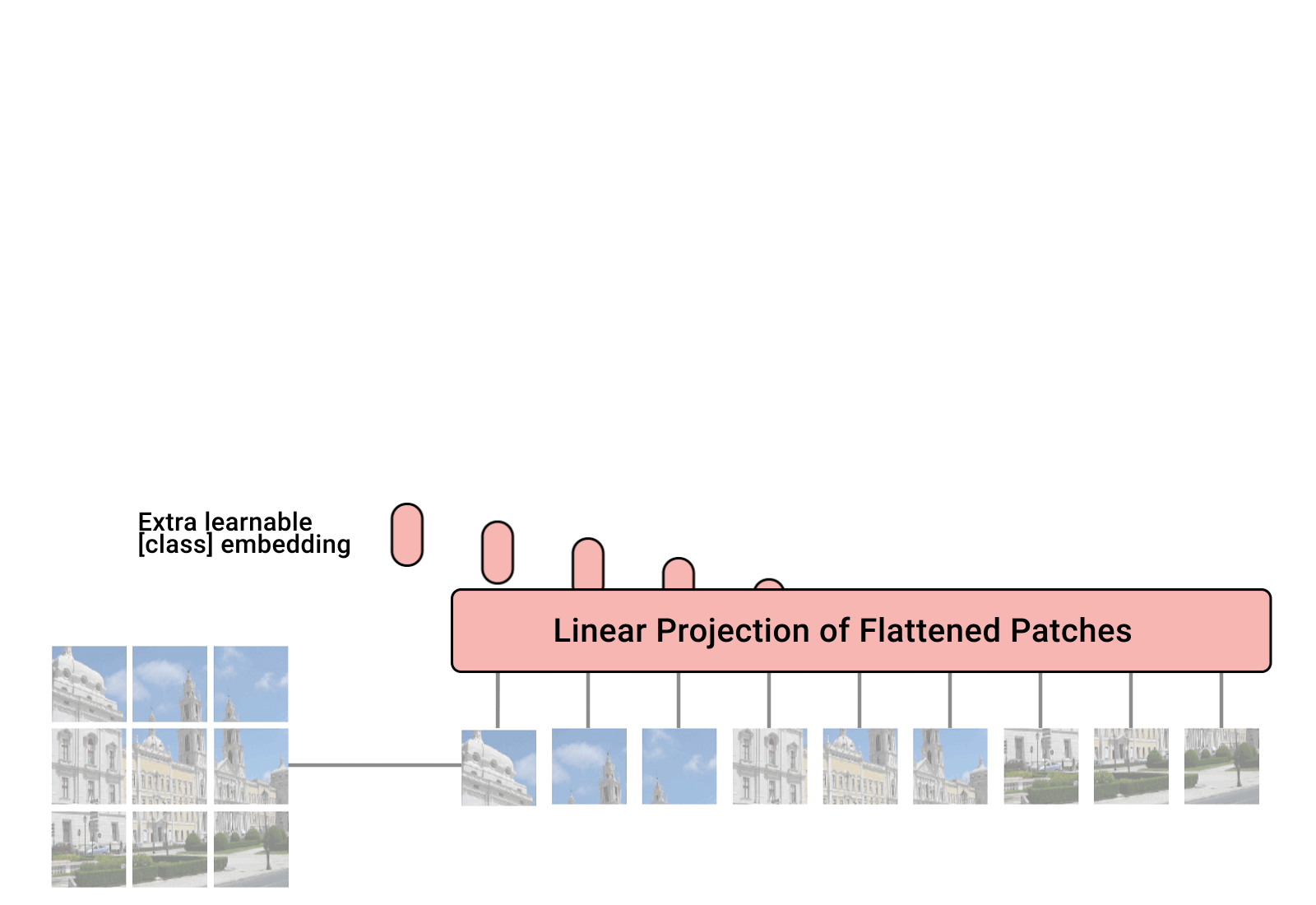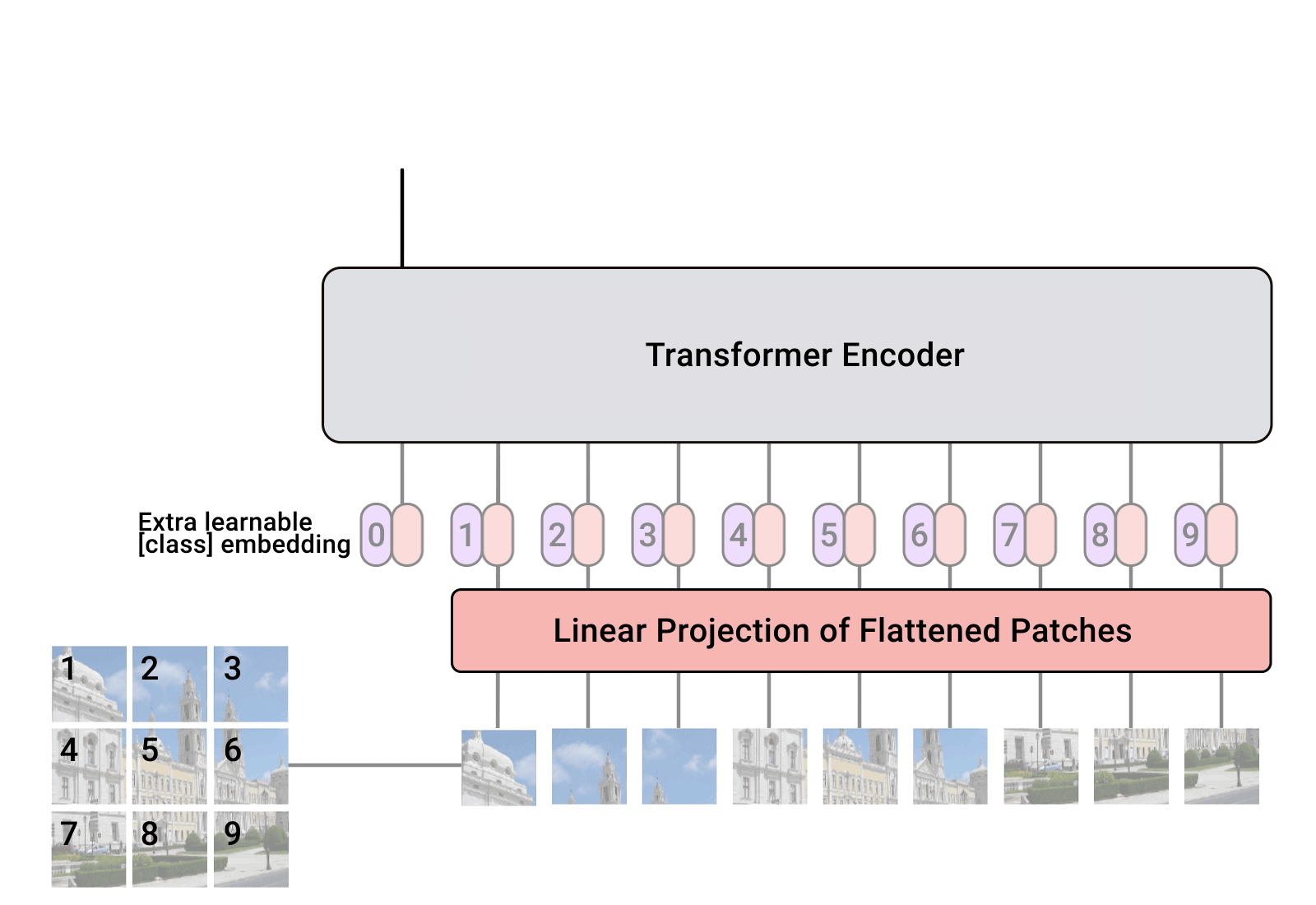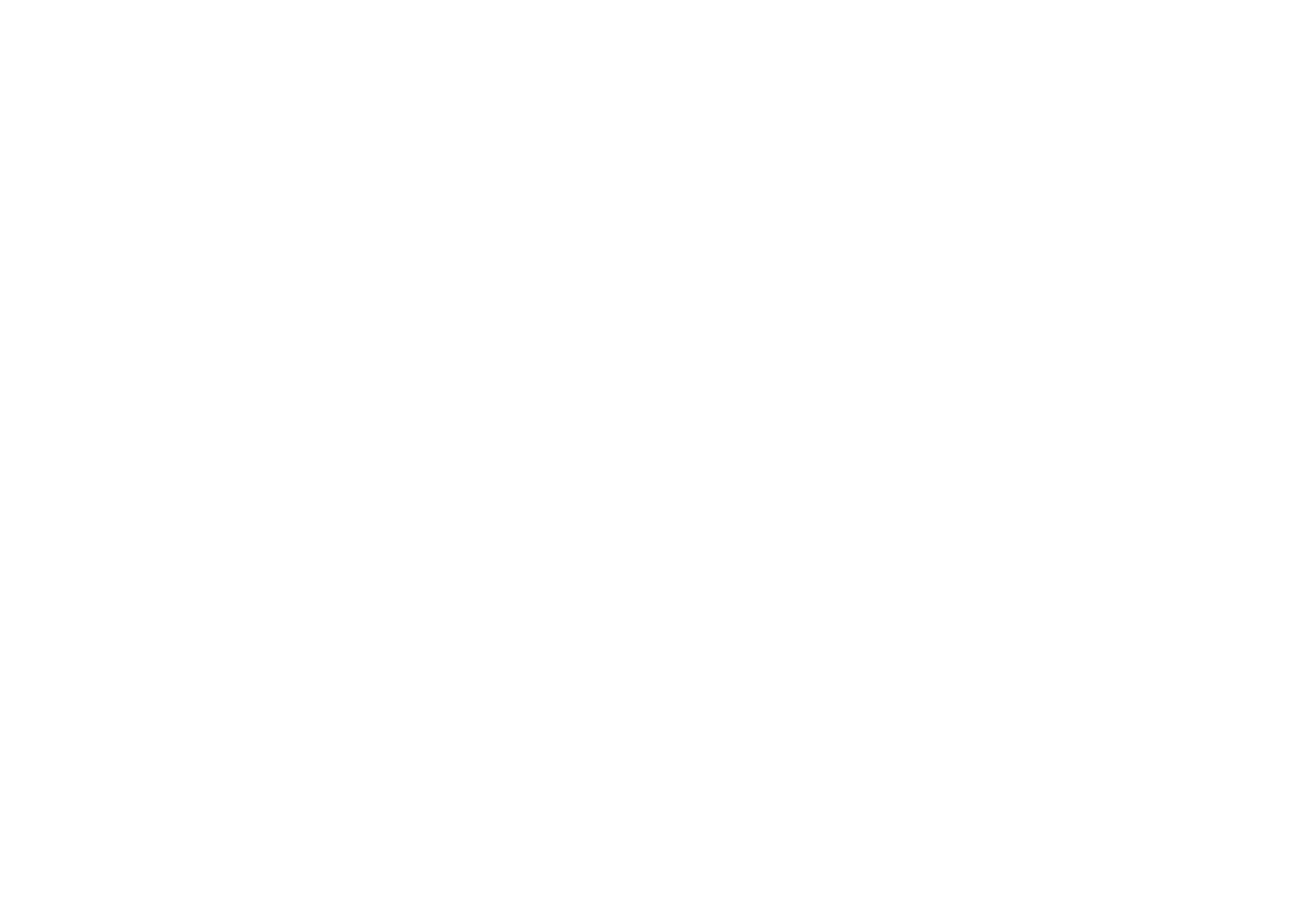SAM论文细读

SAM论文细读
Spark Fly论文地址:https://arxiv.org/abs/2304.02643
项目地址:Segment Anything
项目演示:https://segment-anything.com/demo
基本思想:
1.零次学习:

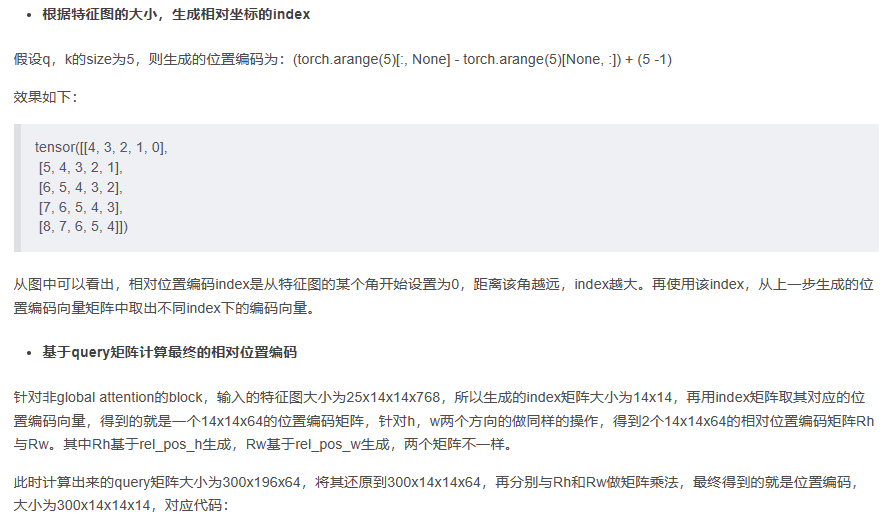
下图所示:
利用过去的知识(马,老虎,熊猫和斑马的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
2.结构分析
SAM模型大致上分成3个模块,一个标准的vit构成的image encoder、一个prompt encoder和一个mask decoder。其中:
- Image encoder: 用于输出image embedding;
- prompt encoder:用于接收point、box、txt的编码信息,并且与image embedding组合到一起送入mask decoder中;
- mask decoder:将上述两个encoder的编码信息转化为mask输出。
一、image encoder
(1)、复习一下
先复习一下关于vit的东西。
模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder
- MLP Head(最终用于分类的层结构)
工作流程如下:
ViT的工作流程,如下:
- 将一张图片分成patches
- 将patches铺平
- 将铺平后的patches的线性映射到更低维的空间
- 添加位置embedding编码信息
- 将图像序列数据送入标准Transformer encoder中去
- 在较大的数据集上预训练
- 在下游数据集上微调用于图像分类
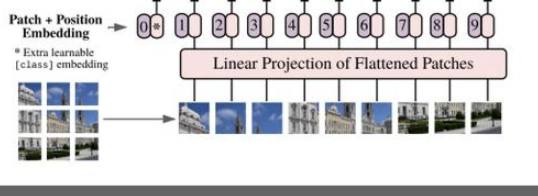
步骤1、将图片转换成patches序列
这一步很关键,为了让Transformer能够处理图像数据,第一步必须先将图像数据转换成序列数据,但是怎么做呢?假如我们有一张图片,patch大小为,那么我们可以创建个图像patches,可以表示为,其中,就是序列的长度,类似一个句子中单词的个数。在上面的图中,可以看到图片被分为了9个patches。
步骤2、将Patches铺平
在原论文中,作者选用的patch大小为16,那么一个patch的shape为(3,16,16),维度为3,将它铺平之后大小为3x16x16=768。即一个patch变为长度为768的向量。不过这看起来还是有点大,此时可以使用加一个Linear transformation,即添加一个线性映射层,将patch的维度映射到我们指定的embedding的维度,这样就和NLP中的词向量类似了。
步骤3、添加Position embedding
与CNNs不同,此时模型并不知道序列数据中的patches的位置信息。所以这些patches必须先追加一个位置信息,也就是图中的带数字的向量。实验表明,不同的位置编码embedding对最终的结果影响不大,在Transformer原论文中使用的是固定位置编码,在ViT中使用的可学习的位置embedding 向量,将它们加到对应的输出patch embeddings上。
步骤4、添加class token
在输入到Transformer Encoder之前,还需要添加一个特殊的class token,这一点主要是借鉴了BERT模型。添加这个class token的目的是因为,ViT模型将这个class token在Transformer Encoder的输出当做是模型对输入图片的编码特征,用于后续输入MLP模块中与图片label进行loss计算。
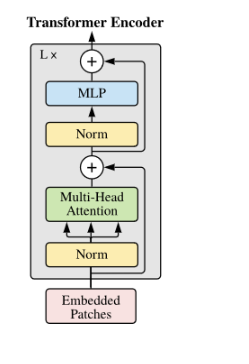
步骤5、输入Transformer Encoder
将patch embedding和class token拼接起来输入标准的Transformer Encoder中。 Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention、Dropout和MLP Block几部分组成。
步骤6、分类
注意Transformer Encoder的输出其实也是一个序列,但是在ViT模型中只使用了class token的输出,将其送入MLP模块中,去输出最终的分类结果。
Embedding层
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,正是Transformer想要的。
这里面就是把以前基于NLP的tansformer改成为图像的可输入,图像也变成二维矩阵。
Transformer Encoder
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由Layer Norm、Multi-Head Attention、Dropout和MLP Block几部分组成。
MLP Head
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
参数说明
(2)、结构说明
- 输入图像进入网络,先经过一个卷积base的patch_embedding:取16*16为一个patch,步长也是16,这样feature map的尺寸就缩小了16倍,同时channel从3映射到768。
- patch_embed过后加positional_embedding:positional_embedding是个可学习的参数矩阵,初始化是0。
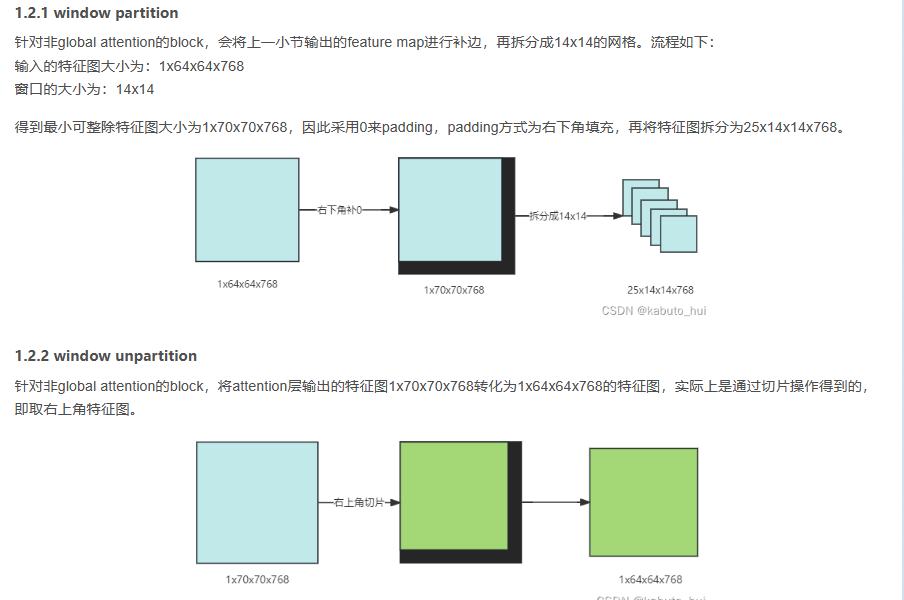
- 加了positional_embedding后的feature map过16个transformer block,其中12个transformer是基于window partition(就是把特征图分成14*14的windows做局部的attention)的attn模块,和4个全局attn,这4个全局attn是穿插在windowed attention中的。
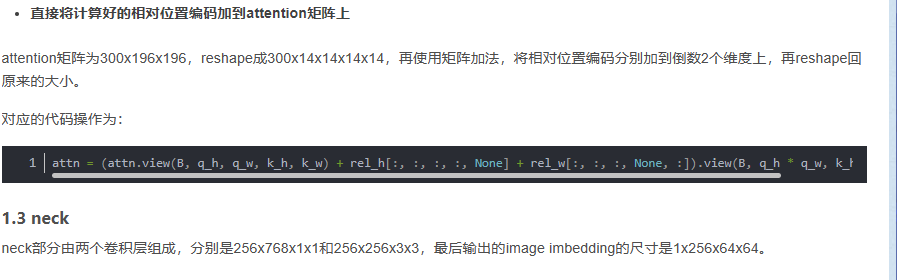
- 最后过两层卷积(neck)把channel数降到256,这就是最终的image embedding的结果
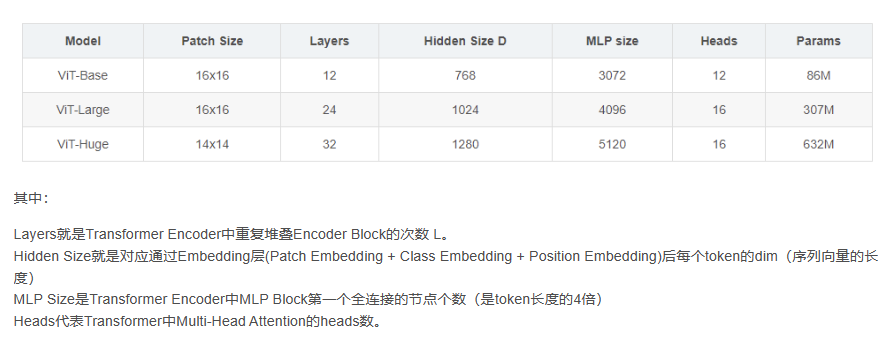
从结构上看,sam的encoder部分就是堆叠transformer的block结构,最后再跟一个neck,调整输出embedding的维度。Meta开源了三个模型,分别是vit_h, vit_l和vit_b,这三个模型的区别仅仅在于内部patch embedding维度、transformer的block的个数以及每个block中head的数量和全局attention的index:
1.1 图片分patch
原图进入网络之后,按照最大边长补充成方形,再resize到1024x1024。
1024x1024x3的图片输入进入网络后,首先使用一个16x16,stride=16,输出channel数为patch embedding维度的二维卷积。以vit_b为例,patch embedding的维度是768,因此经过卷积之后,图片变成了768x64x64的feature map,再调整维度就变成64x64x768。
在该feature map基础上,会再加一个绝对位置编码(absolute positional embedding),所谓绝对位置编码是指生成一组与feature map同样大小(64x64x768)的可学习参数,初始化时一般为0。
1.2 attention block
二、 Prompt encoder
根据输入的point和boxs返回sparse embedding, 根据mask返回dense embeddings。
PromptEncoder属于轻量化的结构,用于对输入模型的points、boxes和masks信息进行编码,将其统一为空间特征编码的格式。其对points、boxes和masks编码时允许有部分值空缺(空缺使用默认值),其将points和boxes组装为sparse_embeddings,将mask组装为dense_embeddings 其对mask的采样由多个attention层实现,具体可见mask_downscaling函数
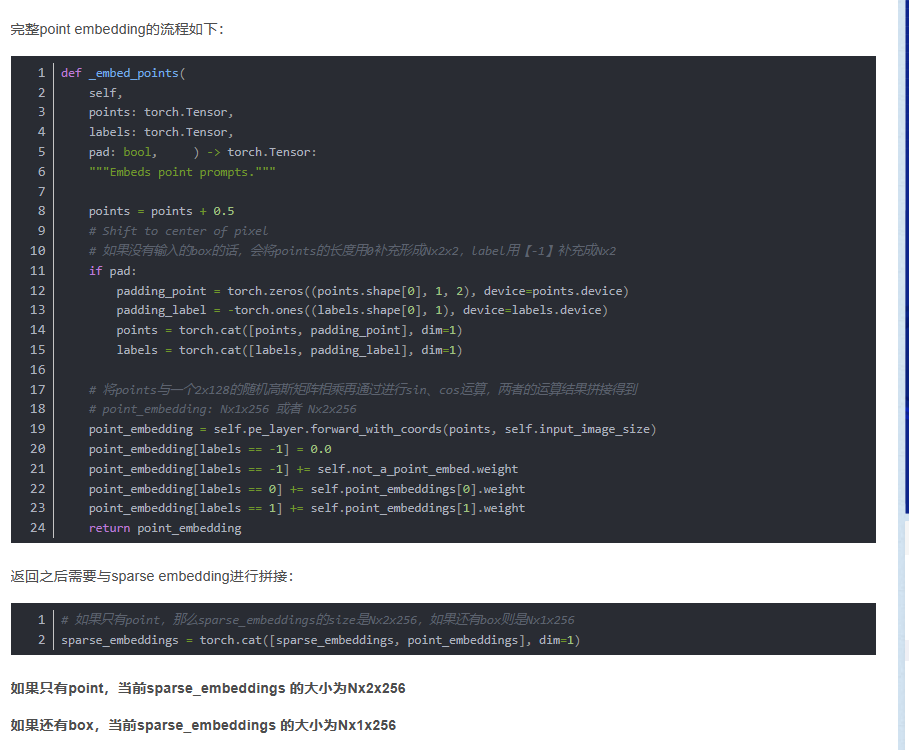
point embedding
- step1:首先生成一组可学习的向量point embedding,大小为:4x1x256:
4代表了表示pos/neg + 2 box corners,即demo里面的添加点和消除点、以及box框的左上角和右下角;
0:neg,对应demo中的消除点
1:pos,对应demo中的添加点
2:代表box左上角点
3:代表box右下角点
- step2:再生成一组可学习的向量not_a_point_embed,大小为1x256,用于表示该位置不是一个点
- step3:如果传入的prompt里面没有bbox,则补充一个【0,0】点到每个point后面,其对应的label为-1
- step4:如果传入的还有bbox,此时的point大小为Nx1x2,label为Nx1
- step5:再根据point计算point embedding,其流程如下:
横纵坐标先归一化,即都除以输入的尺寸(1024, 1024);
再将point矩阵与一个随机高斯矩阵(2x128)矩阵相乘得到Nxax128的矩阵coord,其中(a=2表示只有point,a=1表示还有box作为prompt输入);
再分别对coord计算sin和cos,拼接矩阵得到最终的point embedding(Nxax256)
- step:6再根据label,给point embedding加上之前生成的可学习的embeding向量
box embedding
bbox一般有2个点,其编码步骤如下:
step1: 和point一样,先四个点resize为Nx2x2;
step2: 再使用point embedding编码的方式,得到corner_embedding,
step3: 再加上之前生成的可学习的embeding向量;
最后输出的corner_embedding大小为Nx2x256。
最后输出的box的embedding的尺寸是Nx2x256。
合并(concat)point embedding和corner embedding,可以得到sparse embedding:
全都没有:sparse embedding(1x0x256)
如果只有point:sparse embedding(Nx2x256)
如果只有box:sparse embedding(Nx2x256)
piont、box都有:sparse embedding(Nx3x256)
mask embedding
那么对于mask这类的dense prompt,他的映射就比较简单粗暴。在输入prompt encoder之前,先要把mask降采样到4x,再过两个2x2,stride=2的卷积,这样尺寸又降了4x,就和降了16x的图像特征图尺寸一致了,再过一个1*1的卷积,把channel也升到256。如果没有提供mask,也就是我们实际inference时候的场景,这个结构会直接返回一个描述“没有mask”特征的特征图
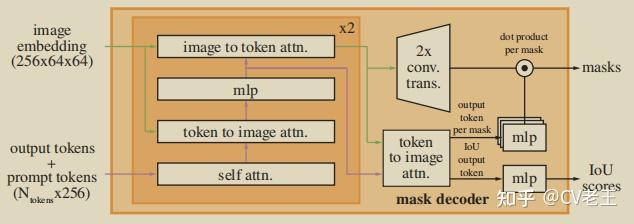
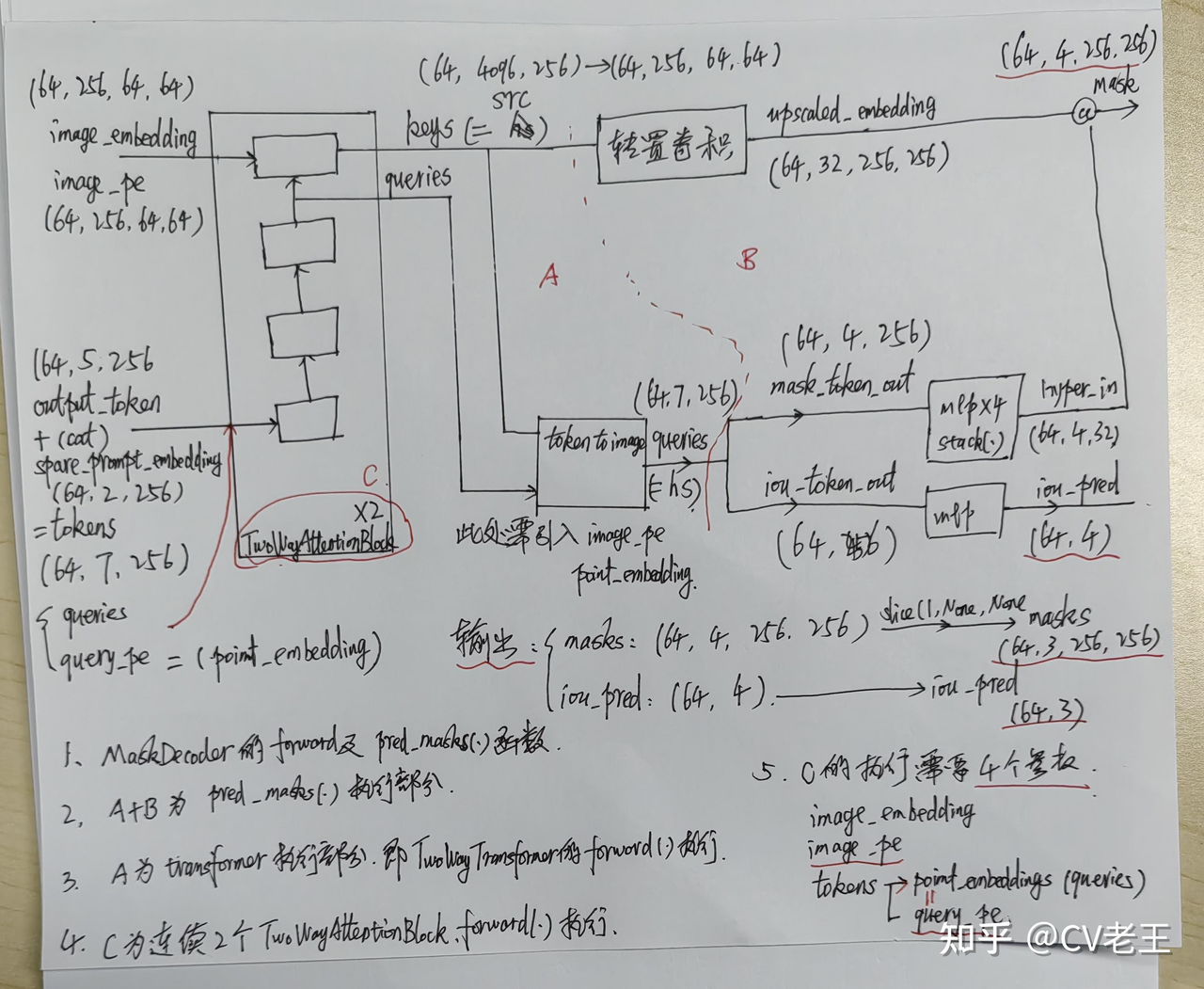
三、mask decoder
decoder的结构之所以看起来复杂,主要原因是prompt embedding和image embedding在这个结构中反复融合并且反复更新,从这里同样可以看出prompt在这个任务中的重要地位。
我们从左至右逐步分析decoder的流程,
- 在prompt embedding进入decoder之前,先在它上面concat了一组可学习的output tokens,output tokens由两个部分构成:
- 一个是iou token,它会在后面被分离出来用于预测iou的可靠性(对应结构图右侧的IoU output token),它受到模型计算出的iou与模型计算出的mask与GT实际的iou之间的MSE loss监督;
- 另一个是mask token,它也会在后面被分离出来参与预测最终的mask(对应结构图右侧的output token per mask),mask受到focal loss和dice loss 20:1的加权组合监督。
- 这两个token的意义我感觉比较抽象,因为理论来说进入decoder的变量应该是由模型的输入,也就是prompt和image的映射构成,但这两个token的定义与prompt和image完全没有关系,而是凭空出现的。从结果反推原因,只能把它们理解成对模型的额外约束,因为它们两个参与构成了模型的两个输出并且有loss对他们进行监督。
- 最终prompt embedding(这一步改名叫prompt token)和刚才提到这两个token concat到一起统称为tokens进入decoder。
- image embedding在进入decoder之前也要进行一步操作:dense prompt由于包含密集的空间信息,与image embedding所在的特征空间一致性更高,所以直接与image embedding相加融合。因为后面要与prompt做cross attention融合,这里还要先算一下image embedding的位置编码。
- 接下来{image embedding,image embedding的位置编码,tokens}进入一个两层transformer结构的decoder做融合。值得注意的是,在transformer结构中,为了保持位置信息始终不丢失,每做一次attention运算,不管是self-attention还是cross-attention,tokens都叠加一次初始的tokens,image embedding都叠加一次它自己的位置编码,并且每个attention后边都接一个layer_norm。
- tokens先过一个self-attention。
- tokens作为q,对image embedding做cross attention,更新tokens。
- tokens再过两层的mlp做特征变换。
- image embedding作为q,对tokens做cross attention,更新image embedding。
- 更新后的tokens作为q,再对更新后的image embedding做cross attention,产生最终的tokens。
- 更新后的image embedding过两层kernel_size=2, stride=2的转置卷积,升采样到4x大小(依然是4x降采样原图的大小),产生最终的image embedding。
- 接下来兵分两路:
- mask token被从tokens中分离出来(因为他一开始就是concat上去的,可以直接按维度摘出来),过一个三层的mlp调整channel数与最终的image embedding一致,并且他们两个做矩阵乘法生成mask的预测。
- iou token被从tokens中分离出来,也过一个三层的mlp生成最终的iou预测。
- 最后,如前文所述,分别对mask的预测和iou预测进行监督,反向传播,更新参数。